显卡运行ai程序有什么好处?性能提升明显吗?
- 电器技巧
- 2025-05-10
- 64
- 更新:2025-05-09 18:46:09
随着人工智能技术的快速发展,AI程序的应用已经渗透到我们生活的方方面面,而硬件设备尤其是显卡的性能对AI程序的运行效率起着至关重要的作用。在本文中,我们将探讨使用显卡运行AI程序的具体好处以及性能提升是否明显,从多角度分析显卡技术对人工智能领域的重要贡献。
显卡对AI程序运行的影响
AI程序与显卡的天然契合
显卡,尤其是NVIDIA的GPU,被广泛应用于AI领域。这是由于GPU具有强大的并行处理能力,可以在同一时间内处理成千上万个计算任务,这对于需要大量矩阵运算和数据处理的AI算法来说是极其有利的。AI中的深度学习模型,如卷积神经网络(CNNs)、递归神经网络(RNNs)和长短期记忆网络(LSTMs)等,都可以从GPU的并行处理能力中受益。
使用高性能显卡运行AI程序能显著提升运算速度。传统的CPU架构虽然拥有强大的单核处理能力,但在处理大量并行计算任务时效率并不理想。显卡通过其成百上千的计算核心,可以在同等时间内完成更多的计算工作,从而大幅提高模型的训练和推理速度。
显卡的使用有助于减少成本。虽然高性能显卡的单个购买成本可能较高,但由于其出色的处理速度,可以在更短的时间内完成AI任务,这样就可以减少服务器的使用时间,长期来看可以节约成本。
显卡性能提升的明显性
显卡性能的提升不仅体现在速度上,还包括了模型训练的精确度。GPU通过其强大的并行计算能力,可以支持更复杂、更深的神经网络结构,从而训练出更为精确的模型。在图像识别、自然语言处理等领域,这种性能的提升尤为明显。
当显卡的计算能力提升时,AI程序的运行稳定性也会得到改善。GPU的稳定性让长时间的AI任务成为可能,这在需要不间断处理大量数据的AI应用中显得尤为重要。

问题式显卡运行AI程序时可能遇到的问题
在使用显卡运行AI程序时,用户可能会遇到诸如显卡驱动更新、CUDA版本适配、内存容量限制等问题。针对这些问题,需要定期检查和更新驱动程序,以及确保CUDA工具包与显卡硬件的兼容性。合理分配内存资源,甚至采用分布式计算方法,也可以有效解决内存不足的瓶颈。
关键词密度与相关性
在撰写文章时,我们需确保核心关键词“显卡运行AI程序的好处”和“性能提升明显”以自然的方式均匀出现在文章的各个部分。同时,我们也会涉及一些长尾关键词,如“GPU并行计算优势”、“深度学习训练速度”等,以满足不同用户的搜索需求。

深度指导与实用技巧
如何选择合适的显卡
对于初学者来说,选择一款适合AI计算的显卡可能会有些困惑。一般来说,选择显卡时需要考虑以下几个方面:
1.核心数量:更多的核心意味着更强的并行计算能力。
2.显存大小:足够的显存可以存储更大的模型和数据集。
3.功耗与散热:显卡在高负载时会产生大量热量,因此良好的散热系统是必要的。
4.兼容性:确保显卡与你使用的开发环境(如TensorFlow、PyTorch等)兼容。
实际应用中的性能评估
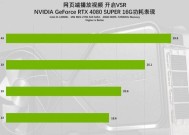
在实际使用中,通过对比不同显卡在相同AI任务中的表现,可以更直观地感受到性能的差异。可以比较不同显卡在图像分类、语言翻译等任务中的准确率、训练时间和推理速度等关键指标。
多角度拓展:显卡技术的发展趋势
显卡技术正不断进步,未来的发展趋势可能包括:
1.新的计算架构:如更高效的并行处理单元设计。
2.高速互连技术:使得显卡间的数据传输更加迅速。
3.AI优化的硬件加速:专门针对深度学习算法设计的硬件加速器。
4.能耗比的进一步提高:在保持性能的同时减少能耗。

结语
通过上述分析,我们可以清晰地看到,显卡在运行AI程序方面拥有诸多优势,并且随着技术的进步,其性能提升将变得更加明显。对于AI领域的研究者和开发者来说,合理选择和利用显卡资源,将能极大地提高工作效率和AI模型的性能。
综合以上,显卡对于AI程序的运行不仅提供了速度上的优势,还通过增强模型复杂度和精确度为AI领域的发展带来了实质性的推动作用。随着技术的不断进步,显卡与AI程序的融合将更加紧密,为未来的技术创新提供坚实的硬件基础。






热门文章

投影仪突然断电应对方法大揭秘(如何处理突发断电情况,保证投影会议顺利进行)
2025-08-19
如何正确清理冰柜(保持冰柜清洁)
2025-08-19
解密空调外风机工作一会儿就停的原因(揭秘空调外风机突然停止运转的几大主要因素)
2025-08-22
解决燃气灶频繁断电的方法(告别不断停电)
2025-08-21
电脑无法连接鼠标的解决方法(快速排除电脑无法连接鼠标的常见问题)
2025-08-21
怎样修复冰箱冷冻皮破损的方法(保护冷冻皮)
2025-08-24
中央空调布线方法详解(一步步教你实现中央空调的有效布线)
2025-08-26
海尔热水器温度设置及统一维修解决方案(提高生活质量)
2025-08-22